- 01Runtime shape
- Local server, browser UI, and pipeline core
- 02Model support
- SD1.5, SDXL, Flux, LoRAs, and enhancement passes
- 03Performance focus
- Xformers, BFloat16, WaveSpeed, and Stable-Fast
- 04Product surface
- Queue, history, presets, previews, uploads, and API
why it matters
- About 30% less inference time than the open-source baselines, and it got into the Ready Tensor CV Projects Expo 2024.
- It works as a browser app and as lower-level execution you can drive directly.
- The speedups (Xformers, BFloat16, WaveSpeed, Stable-Fast) are wired into the execution path.
visuals

engineering notes
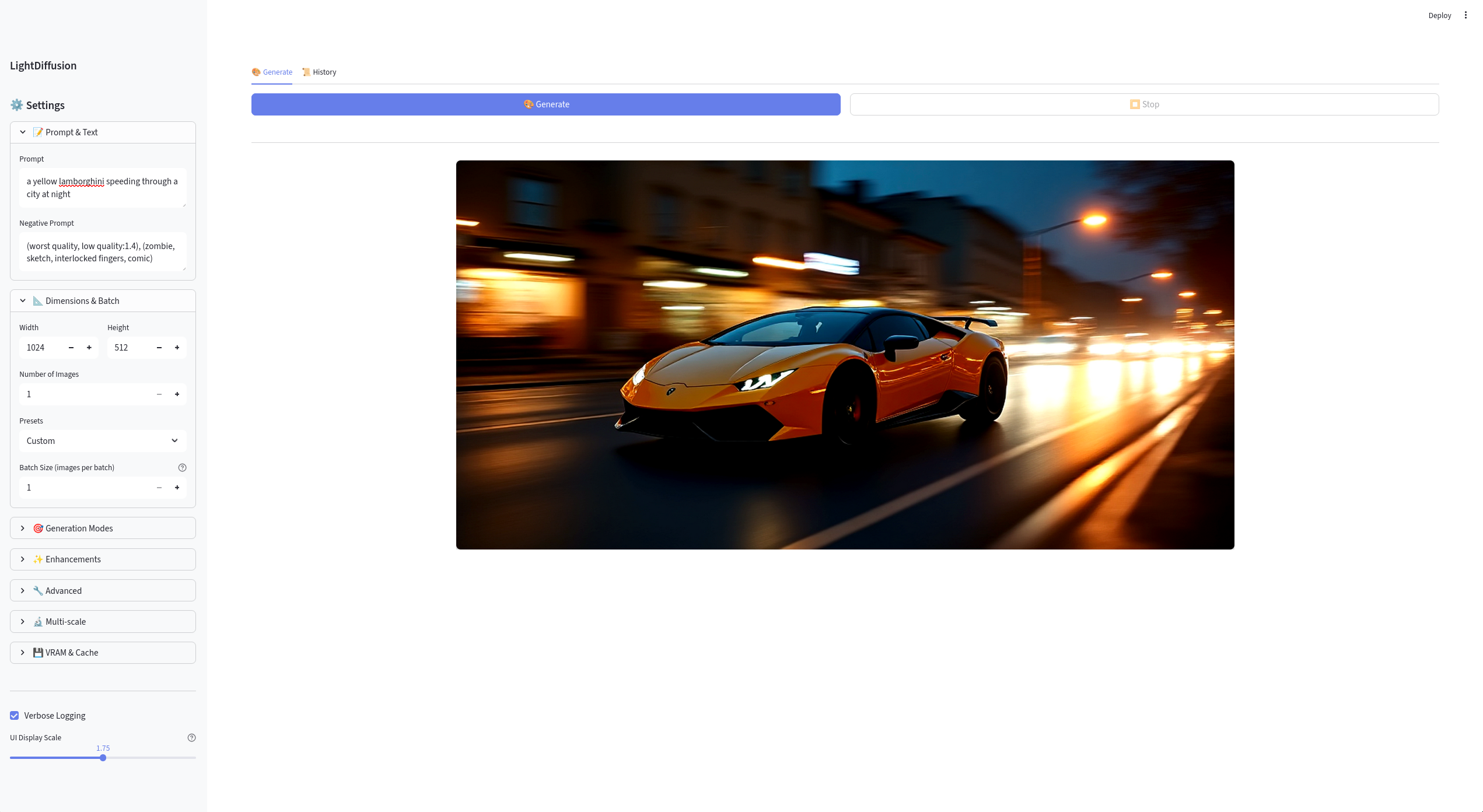
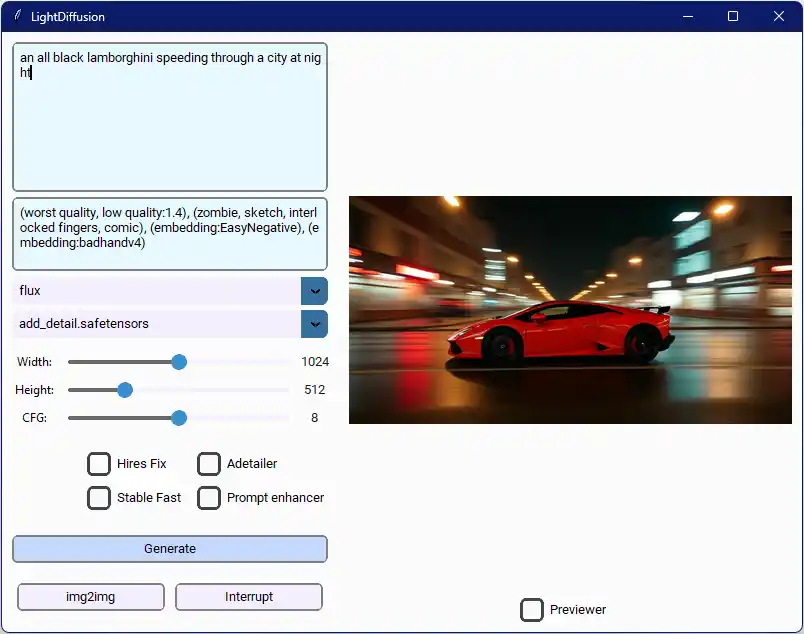
LightDiffusion-Next is a local image-generation system built around a pipeline core, a queueing server, and a web interface. The project includes a complete setup guide, API docs, and a breakdown of the architecture and performance optimizations.
The speed work
The first version of this project measured about 30% less inference time than open-source baselines, earning a spot in the Ready Tensor CV Projects Expo 2024. The speedup comes from:
- Scheduler optimizations: reworking the sampling loop instead of using the stock reference implementation.
- VRAM tensor management: controlling exactly where and when tensors are allocated in memory instead of delegating it to the framework.
It also wires Xformers, BFloat16, WaveSpeed, and Stable-Fast into the execution path.
The workflow
It’s built to be used repeatedly, with:
- prompt and negative prompt, presets, and generation modes
- enhancement passes: Hires-Fix, ADetailer, prompt enhancement, img2img
- queue, history, output previews, and uploads
- a REST API and deployment paths (including a hosted HuggingFace Space)
Architecture
The main pieces:
- generation settings go through one shared pipeline context, no per-UI branches
- model families (SD1.5, SDXL, Flux, LoRAs) get assembled from diffusion, encoder, and VAE pieces
- long jobs are queueable, not blocking calls
- the frontend is kept separate from the pipeline